Overview
This project automates data collection from E-flux listings to build a network of exhibitions, institutions, and artists. It focuses on reliable parsing and entity reconciliation for downstream network analysis.
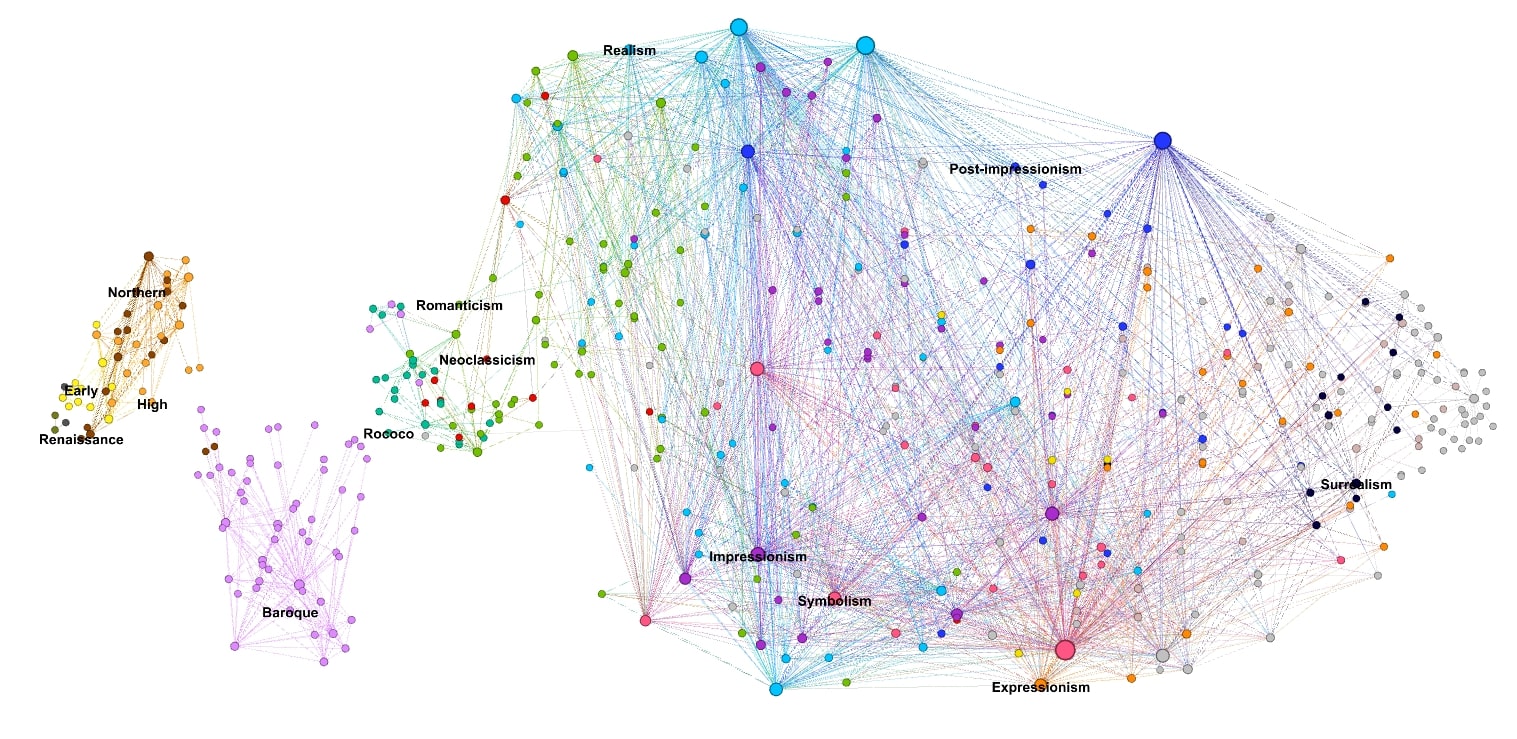
The resulting dataset supports research on cultural diffusion and collaboration patterns across global art institutions.
Key features
- Scraped and normalized thousands of exhibition listings.
- Built entity matching to connect venues, artists, and shows.
- Created a cleaned graph-ready dataset for analytics workflows.
- Documented repeatable scraping and validation steps.
Technical approach
Python scraping pipelines, structured data validation, and scheduled refresh jobs power the dataset. Outputs are stored in a reproducible format for analysis.
Results & impact
The E-flux dataset expanded the coverage of art-world networks and enabled new research on institutional influence and collaboration.